Day 1
Current build
The current pipeline involves collecting a list of grand exchange items and then collecting the 5m time-series for each of those items using the wiki APIs which are graciously provided.
We collect the list because there is a chance a new item has been released, but it probably could run less frequently than it does, either way its pretty cheap.
The 5m time series collects up to 365 points, this gives 365 * 5 minutes ~1.27 days, so we shouldn't miss anything, collecting at this rate gives high latency but I just want to start collecting the data for now so slow batches is fine
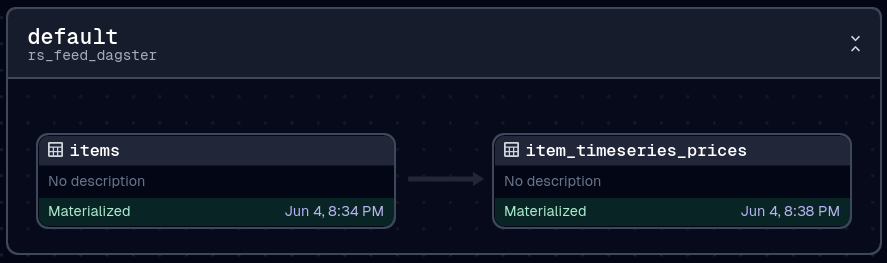
This all runs every 12h and takes about 5 minutes to process at the moment
orchestrator
Dagster is used for orchestration, running it using Dagster+ on serverless so thats 0.0005c per minute * 20 minutes per day * 31 days ~ $1.6 so that's pretty acceptable, and a $10 flag fall too
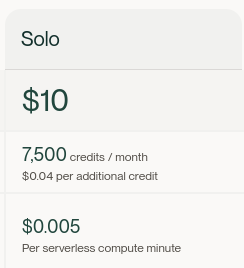
The setup with Dagster cloud is a bit awkward, for one the tooling was injected directly into my repo as a commit using my user, no PR. Second, dagster requires some specific tooling setups, namely setup.py which I haven't been using lately so is a bit annoying to have back. Finally, the method to add secrets is heavy click-ops and no CLI methods or bulk imports available.
That said, getting over those teething issues, and everything seems to be running quite smoothly now!
The code implementation needs a lot of work!
datastore
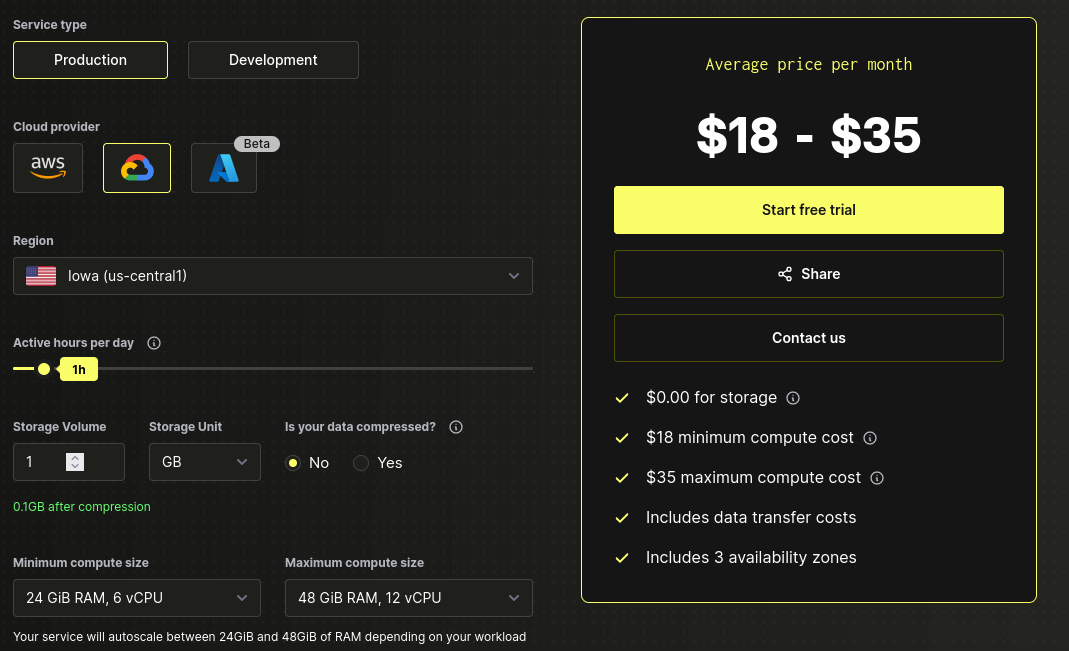
The datastore in use is Clickhouse, the free tier looks pretty good and wanted to check it out, it will probably be too expensive to run full time, but it is configured to shut down after 5 minutes and takes only about 30s to launch from sleep.
This should amount to no more than 20minutes a day so $9-16 for a month according to this calculator
schema
using Atlas to manage the schema, this is a new one for me, but I see good value in it. Not sure whether to manage the entire schema with it or just loading tables. Probably both for production?
Helpful since Clickhouse doesn't allow for create table x as select type queries.
the actual schema is this, very simple, essentially a direct copy of the API for time series and items just an id, some enrichment to be done.
table "item_prices" {
schema = schema.default
engine = sql("SharedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')")
settings = {
index_granularity = 8192
}
column "id" {
null = false
type = Int16
}
column "timestamp" {
null = false
type = Int64
}
column "avgHighPrice" {
null = true
type = sql("Nullable(Float32)")
}
column "avgLowPrice" {
null = true
type = sql("Nullable(Float32)")
}
column "highPriceVolume" {
null = false
type = Int128
}
column "lowPriceVolume" {
null = false
type = Int128
}
primary_key {
columns = [column.id, column.timestamp]
}
}
table "items" {
schema = schema.default
engine = sql("SharedReplacingMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')")
settings = {
index_granularity = 8192
}
column "id" {
null = false
type = Int16
}
primary_key {
columns = [column.id]
}
}
schema "default" {
engine = sql("Replicated('/clickhouse/databases/default', '{shard}', '{replica}')")
}